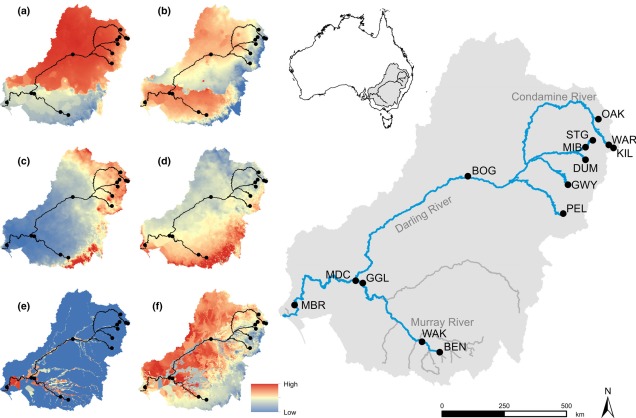
For anyone who has had to study geography at some point in their education, you’d likely be familiar with the idea of river courses drawn on a map. They’re so important, in fact, that they are often the delimiting factor in the edges of countries, states or other political units. Water is a fundamental requirement of all forms of life and the riverways that scatter the globe underpin the maintenance, structure and accumulation of a large swathe of biodiversity.
One very effective summary statistic that we might choose to use is the site-frequency spectrum (aka the allele frequency spectrum). Not to be confused with other measures of allele frequency which we’ve discussed before (like Fst), the site-frequency spectrum (abbreviated to SFS) is essentially a histogram of how frequent certain alleles are within our dataset. To do this, the SFS classifies each allele into a certain category based on how common it is, tallying up the number of alleles that occur at that frequency. The total number of categories would be the maximum number of possible alleles: for organisms with two copies of every chromosome (‘diploids’, including humans), this means that there are double the number of samples included. For example, a dataset comprised of genomic sequence for 5 people would have 10 different frequency bins.
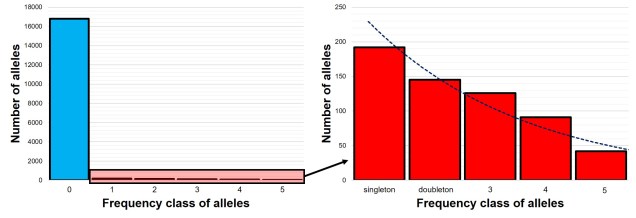
An example of the 1DSFS for a single population, taken from a real dataset from my PhD. Left: the full site-frequency spectrum, counting how many alleles (y-axis) occur a certain number of times (categories of the x-axis) within the population. In this example, as in most species, the vast majority of our DNA sequence is non-variable (frequency = 0). Given the huge disparity in number of non-variable sites, we often select on the variable ones (and even then, often discard the 1 category to remove potential sequencing errors) and get a graph more like the right. Right: the ‘realistic’ 1DSFS for the population, showing a general exponential decline (the blue trendline) for the more frequent classes. This is pretty standard for an SFS. ‘Singleton’ and ‘doubleton’ are alternative names for ‘alleles which occur once’ and ‘alleles which occur twice’ in an SFS.
Expanding the SFS to multiple populations
Further to this, we can expand the site-frequency spectrum to compare across populations. Instead of having a simple 1-dimensional frequency distribution, for a pair of populations we can have a grid. This grid specifies how often a particular allele occurs at a certain frequency in Population A and at a different frequency in Population B. This can also be visualised quite easily, albeit as a heatmap instead. We refer to this as the 2-dimensional SFS (2DSFS).
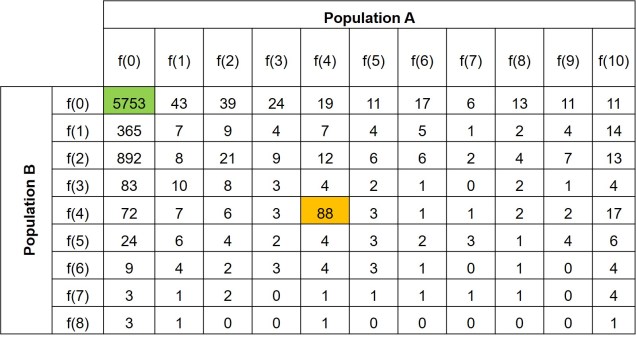
An example of a 2DSFS, also taken from my PhD research. In this example, we are comparing Population A, containing 5 individuals (as diploid, 2 x 5 = max. of 10 occurrences of an allele) with Population B, containing 4 individuals. Each row denotes the frequency at which a certain allele occurs in Population B whilst the columns indicate the frequency a certain allele occurs in Population A. Each cell therefore indicates the number of alleles that occur at the exact frequency of the corresponding row and column. For example, the first cell (highlighted in green) indicates the number of alleles which are not found in either Population A or Population B (this dataset is a subsample from a larger one). The yellow cell indicates the number of alleles which occur 4 times in Population B and also 4 times in Population A. This could mean that in one of those Populations 4 individuals have one copy of that allele each, or two individuals have two copies of that allele, or that one has two copies and two have one copy. The exact composition of how the alleles are spread across samples within each population doesn’t matter to the overall SFS.
The same concept can be expanded to even more populations, although this gets harder to represent visually. Essentially, we end up with a set of different matrices which describe the frequency of certain alleles across all of our populations, merging them together into the joint SFS. For example, a joint SFS of 4 populations would consist of 6 (4 x 4 total comparisons – 4 self-comparisons, then halved to remove duplicate comparisons) 2D SFSs all combined together. To make sense of this, check out the diagrammatic tables below.
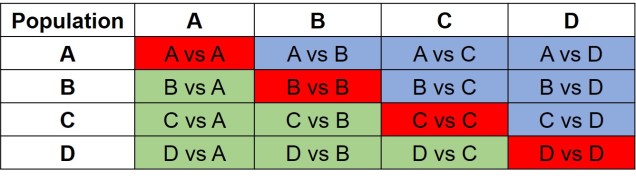
A summary of the different combinations of 2DSFSs that make up a joint SFS matrix. In this example we have 4 different populations (as described in the above text). Red cells denote comparisons between a population and itself – which is effectively redundant. Green cells contain the actual 2D comparisons that would be used to build the joint SFS: the blue cells show the same comparisons but in mirrored order, and are thus redundant as well.Expanding the above jSFS matrix to the actual data, this matrix demonstrates how the matrix is actually a collection of multiple 2DSFSs. In this matrix, one particular cell demonstrates the number of alleles which occur at frequency xin one population and frequency yin another. For example, if we took the cell in the third row from the top and the fourth column from the left, we would be looking at the number of alleles which occur twice in Population B and three times in Population A. The colour of this cell is moreorless orange, indicating that ~50 alleles occur at this combination of frequencies. As you may notice, many population pairs show similar patterns, except for the Population C vs Population D comparison.
The different forms of the SFS
Which alleles we choose to use within our SFS is particularly important. If we don’t have a lot of information about the genomics or evolutionary history of our study species, we might choose to use the minor allele frequency (MAF). Given that SNPs tend to be biallelic, for any given locus we could have Allele A or Allele B. The MAF chooses the least frequent of these two within the dataset and uses that in the summary SFS: since the other allele’s frequency would just be 2N – the frequency of the other allele, it’s not included in the summary. An SFS made of the MAF is also referred to as the folded SFS.
Alternatively, if we know some things about the genetic history of our study species, we might be able to divide Allele A and Allele B into derived or ancestral alleles. Since SNPs often occur as mutations at a single site in the DNA, one allele at the given site is the new mutation (the derived allele) whilst the other is the ‘original’ (the ancestral allele). Typically, we would use the derived allele frequency to construct the SFS, since under coalescent theory we’re trying to simulate that mutation event. An SFS made of the derived alleles only is also referred to as the unfolded SFS.
Applications of the SFS
How can we use the SFS? Well, it can moreorless be used as a summary of genetic variation for many types of coalescent-based analyses. This means we can make inferences of demographic history (see here for more detailed explanation of that) without simulating large and complex genetic sequences and instead use the SFS. Comparing our observed SFS to a simulated scenario of a bottleneck and comparing the expected SFS allows us to estimate the likelihood of that scenario.
A representative example of how a bottleneck causes a shift in the SFS, based on a figure from a previous post on the coalescent. Centre: the diagram of alleles through time, with rarer variants (yellow and navy) being lost during the bottleneck but more common variants surviving (red). Left: this trend is reflected in the coalescent trees for these alleles, with red crosses indicating the complete loss of that allele. Right: the SFS from before (in red) and after (in blue) the bottleneck event for the alleles depicted. Before the bottleneck, variants are spread in the usual exponential shape: afterwards, however, a disproportionate loss of the rarer variants causes the distribution to flatten. Typically, the SFS would be built from more alleles than shown here, and extend much further.
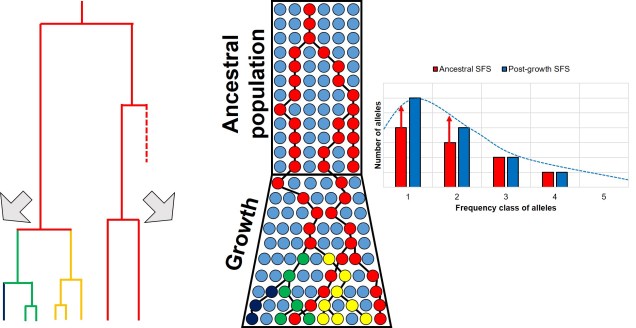
A similar diagram as above, but this time with an expansion event rather than a bottleneck. The expansion of the population, and subsequent increase in Ne, facilitates the mutation of new alleles from genetic drift (or reduced loss of alleles from drift), causing more new (and thus rare) alleles to appear. This is shown by both the coalescent tree (left) and a shift in the SFS (right).
The SFS can even be used to detect alleles under natural selection. For strongly selected parts of the genome, alleles should occur at either high (if positively selected) or low (if negatively selected) frequency, with a deficit of more intermediate frequencies.
Adding to the analytical toolbox
The SFS is just one of many tools we can use to investigate the demographic history of populations and species. Using a combination of genomic technologies, coalescent theory and more robust analytical methods, the SFS appears to be poised to tackle more nuanced and complex questions of the evolutionary history of life on Earth.
Australia is renowned for its unique diversity of species, and likewise for the diversity of ecosystems across the island continent. Although many would typically associate Australia with the golden sandy beaches, palm trees and warm weather of the tropical east coast, other ecosystems also hold both beautiful and interesting characteristics. Even the regions that might typically seem the dullest – the temperate zones in the southern portion of the continent – themselves hold unique stories of the bizarre and wonderful environmental history of Australia.
The two temperate zones
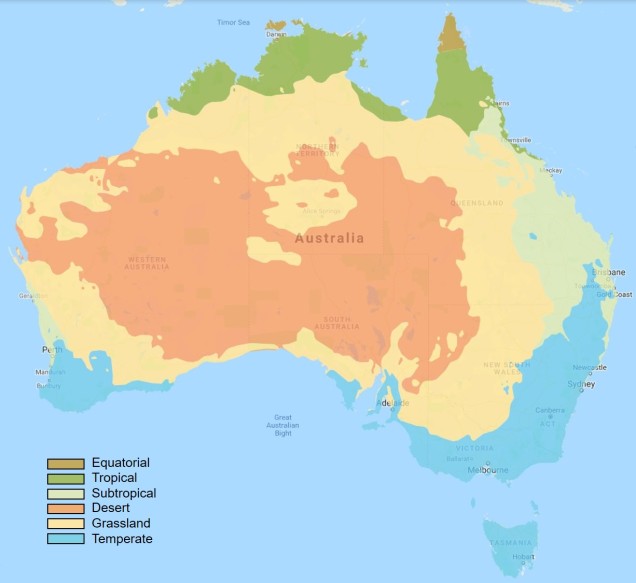
Within Australia, the temperate zone is actually separated into two very distinct and separate regions. In the far south-western corner of the continent is the southwest Western Australia temperate zone, which spans a significant portion. In the southern eastern corner, the unnamed temperate zone spans from the region surrounding Adelaide at its westernmost point, expanding to the east and encompassing Tasmanian and Victoria before shifting northward into NSW. This temperate zones gradually develops into the sub-tropical and tropical climates of more northern latitudes in Queensland and across to Darwin.
The climatic classification (Koppen-Geiger) of Australia’s ecosystems, derived from the Atlas of Living Australia. The light blue region highlights the temperate zones discussed here, with an isolated region in the SW and the broader region of the SE as it transitions into subtropical and tropical climates northward.
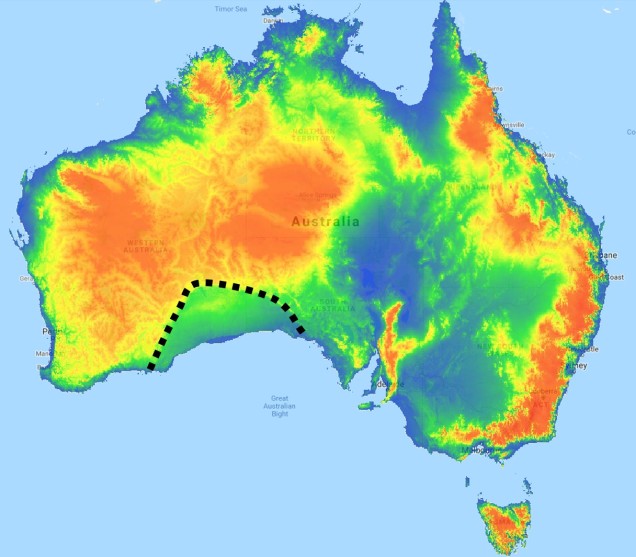
The divide separating these two regions might be familiar to some readers – the Nullarbor Plain. Not just a particularly good location for fossils and mineral ores, the Nullarbor Plain is an almost perfectly flat arid expanse that stretches from the western edge of South Australia to the temperate zone of the southwest. As the name suggests, the plain is totally devoid of any significant forestry, owing to the lack of available water on the surface. This plain is a relatively ancient geological structure, and finished forming somewhere between 14 and 16 million years ago when tectonic uplift pushed a large limestone block upwards to the surface of the crust, forming an effective drain for standing water with the aridification of the continent. Thus, despite being relatively similar bioclimatically, the two temperate zones of Australia have been disconnected for ages and boast very different histories and biota.
A map of elevation across the Australian continent, also derived from the Atlas of Living Australia. The dashed black line roughly outlines the extent of the Nullarbor Plain, a massively flat arid expanse.
The hotspot of the southwest
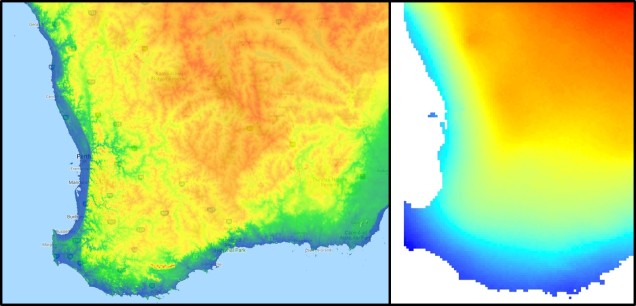
The southwest temperate zone – commonly referred to as southwest Western Australia (SWWA) – is an island-like bioregion. Isolated from the rest of the temperate Australia, it is remarkably geologically simple, with little topographic variation (only the Darling Scarp that separates the lower coast from the higher elevation of the Darling Plateau), generally minor river systems and low levels of soil nutrients. One key factor determining complexity in the SWWA environment is the isolation of high rainfall habitats within the broader temperate region – think of islands with an island.
A figure demonstrating the environmental characteristics of SWWA, using data from the Atlas of Living Australia. Left: An elevation map of the region, showing some mountainous variation, but only one significant steep change along the coast (blue area). Right: A summary of 19 different temperature and precipitation variables, showing a relatively weak gradient as the region shifts inland.
Despite the lack of geological complexity and the perceived diversity of the tropics, the temperate zone of SWWA is the only internationally recognisedbiodiversity hotspot within Australia. As an example, SWWA is inhabited by ~7,000 different plant species, half of which are endemic to the region. Not to discredit the impressive diversity of the rest of the continent, of course. So why does this area have even higher levels of species diversity and endemism than the rest of mainland Australia?
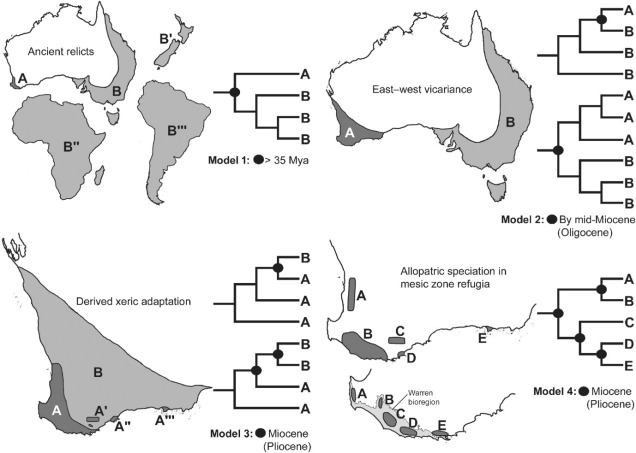
A demonstration of some of the different patterns which might explain the high biodiversity of SWWA, from Rix et al. (2015). These predominantly relate to different biogeographic mechanisms that might have driven diversification in the region, from survivors of the Gondwana era to the more recent fragmentation of mesic habitats.
Well, a number of factors may play significant roles in determining this. One of these is the ancient and isolated nature of the region: SWWA has been separated from the rest of Australia for at least 14 million years, with many species likely originating much earlier than this. Because of this isolation, species occurring within SWWA have been allowed to undergo adaptive divergence from their east coast relatives, forming unique evolutionary lineages. Furthermore, the southwest corner of the continent was one of the last to break away from Antarctica in the dismantling of Gondwana >30 million years ago. Within the region more generally, isolation of mesic (wetter) habitats from the broader, arid (xeric) habitats also likely drove the formation of new species as distributions became fragmented or as species adapted to the new, encroaching xeric habitat. Together, this varies mechanisms all likely contributed in some way to the overall diversity of the region.
The temperate south-east of Australia
Contrastingly, the temperate region in the south-east of the continent is much more complex. For one, the topography of the zone is much more variable: there are a number of prominent mountain chains (such as the extended Great Dividing Range), lowland basins (such as the expansive Murray-Darling Basin) and variable valley and river systems. Similarly, the climate varies significantly within this temperate region, with the more northern parts featuring more subtropical climatic conditions with wetter and hotter summers than the southern end. There is also a general trend of increasing rainfall and lower temperatures along the highlands of the southeast portion of the region, and dry, semi-arid conditions in the western lowland region.
A map demonstrating the climatic variability across the Murray-Darling Basin (which makes up a large section of the SE temperate zone), from Brauer et al. (2018). The different heat maps on the left describe different types of variables; a) and b) represent temperature variables, c) and d) represent precipitation (rainfall) variables, and e) and f) represent water flow variables. Each variable is a summary of a different set of variables, hence the differences.
A complicated history
The south-east temperate zone is not only variable now, but has undergone some drastic environmental changes over history. Massive shifts in geology, climate and sea-levels have particularly altered the nature of the area. Even volcanic events have been present at some time in the past.
One key hydrological shift that massively altered the region was the paleo-megalake Bungunnia. Not just a list of adjectives, Bungunnia was exactly as it’s described: a historically massive lake that spread across a huge area prior to its demise ~1-2 million years ago. At its largest size, Lake Bungunnia reached an area of over 50,000 km2, spreading from its westernmost point near the current Murray mouth although to halfway across Victoria. Initially forming due to a tectonic uplift event along the coastal edge of the Murray-Darling Basin ~3.2 million years ago, damming the ancestral Murray River (which historically outlet into the ocean much further east than today). Over the next few million years, the size of the lake fluctuated significantly with climatic conditions, with wetter periods causing the lake to overfill and burst its bank. With every burst, the lake shrank in size, until a final break ~700,000 years ago when the ‘dam’ broke and the full lake drained.
A map demonstrating the sheer size of paleo megalake Bungunnia at it’s largest extent, taken from McLaren et al. (2012).
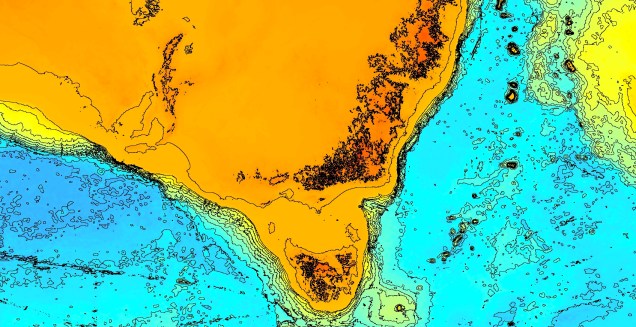
Another change in the historic environment readers may be more familiar with is the land-bridge that used to connect Tasmania to the mainland. Dubbed the Bassian Isthmus, this land-bridge appeared at various points in history of reduced sea-levels (i.e. during glacial periods in Pleistocene cycle), predominantly connecting via the still-above-water Flinders and Cape Barren Islands. However, at lower sea-levels, the land bridge spread as far west as King Island: central to this block of land was a large lake dubbed the Bass Lake (creative). The Bassian Isthmus played a critical role in the migration of many of the native fauna of Tasmania (likely including the Indigenous peoples of the now-island), and its submergence and isolation leads to some distinctive differences between Tasmanian and mainland biota. Today, the historic presence of the Bassian Isthmus has left a distinctive mark on the genetic make-up of many species native to the southeast of Australia, including dolphins, frogs, freshwater fishes and invertebrates.
An elevation (Etopo1) map demonstrating the now-underwater land bridge between Tasmania and the mainland. Orange colours denote higher areas whilst light blue represents lower sections.
Don’t underestimate the temperates
Although tropical regions get most of the hype for being hotspots of biodiversity, the temperate zones of Australia similarly boast high diversity, unique species and document a complex environmental history. Studying how the biota and environment of the temperate regions has changed over millennia is critical to predicting the future effects of climatic change across large ecosystems.
This is based on the idea that for genes that are not related to traits under selection (either positively or negatively), new mutations should be acquired and lost under predominantly random patterns. Although this accumulation of mutations is influenced to some degree by alternate factors such as population size, the overall average of a genome should give a picture that largely discounts natural selection. But is this true? Is the genome truly neutral if averaged?
Non-neutrality
First, let’s take a look at what we mean by neutral or not. For genes that are not under selection, alleles should be maintained at approximately balanced frequencies and all non-adaptive genes across the genome should have relatively similar distribution of frequencies. While natural selection is one obvious way allele frequencies can be altered (either favourably or detrimentally), other factors can play a role.
An example of how linkage disequilibrium can alter allele frequency of ‘neutral’ parts of the genome as well. In this example, only one part of this section of the genome is selected for: the green gene. Because of this positive selection, the frequency of a particular allele at this gene increases (the blue graph): however, nearby parts of the genome also increase in frequency due to their proximity to this selected gene, which decreases with distance. The extent of this effect determines the size of the ‘linkage block’ (see below).
Why might ‘neutral’ models not be neutral?
The assumption that the vast majority of the genome evolves under neutral patterns has long underpinned many concepts of population and evolutionary genetics. But it’s never been all that clear exactly how much of the genome is actually evolving neutrally or adaptively. How far natural selection reaches beyond a single gene under selection depends on a few different factors: let’s take a look at a few of them.
Linked selection
As described above, physically close genes (i.e. located near one another on a chromosome) often share some impacts of selection due to reduced recombination that occurs at that part of the genome. In this case, even alleles that are not adaptive (or maladaptive) may have altered frequencies simply due to their proximity to a gene that is under selection (either positive or negative).
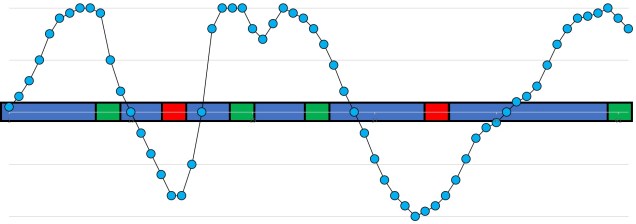
A (perhaps familiar) example of the interaction between recombination (the breaking and mixing of different genes across chromosomes) and linkage disequilibrium. In this example, we have 5 different copies of a part of the genome (different coloured sequences), which we randomly ‘break’ into separate fragments (breaks indicated by the dashed lines). If we focus on a particular base in the sequence (the yellow A) and count the number of times a particular base pair is on the same fragment, we can see how physically close bases are more likely to be coinherited than further ones (bottom column graph). This makes mathematical sense: if two bases are further apart, you’re more likely to have a break that separates them. This is the very basic underpinning of linkage and recombination, and the size of the region where bases are likely to be coinherited is called the ‘linkage block’.
The extent of this linkage effect depends on a number of other factors such as ploidy (the number of copies of a chromosome a species has), the size of the population and the strength of selection around the central locus. The presence of linkage and its impact on the distribution of genetic diversity (LD) has been well documented within evolutionary and ecological genetic literature. The more pressing question is one of extent: how much of the genome has been impacted by linkage? Is any of the genome unaffected by the process?
A cartoonish example of how background selection affects neighbouring sections of the genome. In this example, we have 4 genes (A, B, C and D) with interspersing neutral ‘non-gene’ sections. The allele for Gene B is strongly selected againstby natural selection (depicted here as the Banhammer of Selection). However, the Banhammer is not very precise, and when decreasing the frequency of this maladaptive Gene B allele it also knocks down the neighbouring non-gene sections. Despite themselves not being maladaptive, their allele frequencies are decreased due to physical linkage to Gene B.
This findings have significant implications for our understanding of the process of evolution, and how we can detect adaptation within the genome. In light of this research, there has been heated discussion about whether or not neutral theory is ‘dead’, or a useful concept.
A vague summary of how a large portion of the genome might not actually be neutral. In this section of the genome, we have neutral (blue), maladaptive (red) and adaptive (green) elements. Natural selection either favours, disfavours, or is ambivalent about each of this sections alone. However, there is significant ‘spill-over’ around regions of positively or negatively selected sections, which causes the allele frequency of even the neutral sections to fluctuate widely. The blue dotted line represents this: when the line is above the genome, allele frequency is increased; when it is below it is decreased. As we travel along this section of the genome, you may notice it is rarely ever in the middle (the so-called ‘neutral‘ allele frequency, in line with the genome).
Although I avoid having a strong stance here (if you’re an evolutionary geneticist yourself, I will allow you to draw your own conclusions), it is my belief that the model of neutral theory – and the methods that rely upon it – are still fundamental to our understanding of evolution. Although it may present itself as a more conservative way to identify adaptation within the genome, and cannot account for the effect of the above processes, neutral theory undoubtedly presents itself as a direct and well-implemented strategy to understand adaptation and demography.
A recurring analytical method, both within The G-CAT and the broader ecological genetic literature, is based on coalescent theory. This is based on the mathematical notion that mutations within genes (leading to new alleles) can be traced backwards in time, to the point where the mutation initially occurred. Given that this is a retrospective, instead of describing these mutation moments as ‘divergence’ events (as would be typical for phylogenetics), these appear as moments where mutations come back together i.e. coalesce.
Before we can explore the multitude of applications of the coalescent, we need to understand the fundamental underlying model. The initial coalescent model was described in the 1980s, built upon by a number of different ecologists, geneticists and mathematicians. However, John Kingman is often attributed with the formation of the original coalescent model, and the Kingman’s coalescent is considered the most basic, primal form of the coalescent model.
From a mathematical perspective, the coalescent model is actually (relatively) simple. If we sampled a single gene from two different individuals (for simplicity’s sake, we’ll say they are haploid and only have one copy per gene), we can statistically measure the probability of these alleles merging back in time (coalescing) at any given generation. This is the same probability that the two samples share an ancestor (think of a much, much shorter version of sharing an evolutionary ancestor with a chimpanzee).
Normally, if we were trying to pick the parents of our two samples, the number of potential parents would be the size of the ancestral population (since any individual in the previous generation has equal probability of being their parent). But from a genetic perspective, this is based on the genetic (effective) population size (Ne), multiplied by 2 as each individual carries two copies per gene (one paternal and one maternal). Therefore, the number of potential parents is 2Ne.
A graph of the probability of a coalescent event (i.e. two alleles sharing an ancestor) in the immediatelypreceding generation (i.e. parents) relatively to the size of the population. As one might expect, with larger population sizes there is low chance of sharing an ancestor in the immediately prior generation, as the pool of ‘potential parents’ increases.
If we have an idealistic population, with large Ne, random mating and no natural selection on our alleles, the probability that their ancestor is in this immediate generation prior (i.e. share a parent) is 1/(2Ne). Inversely, the probability they don’t share a parent is 1 − 1/(2Ne). If we add a temporal component (i.e. number of generations), we can expand this to include the probability of how many generations it would take for our alleles to coalesce as (1 – (1/2Ne))t-1 x 1/2Ne.
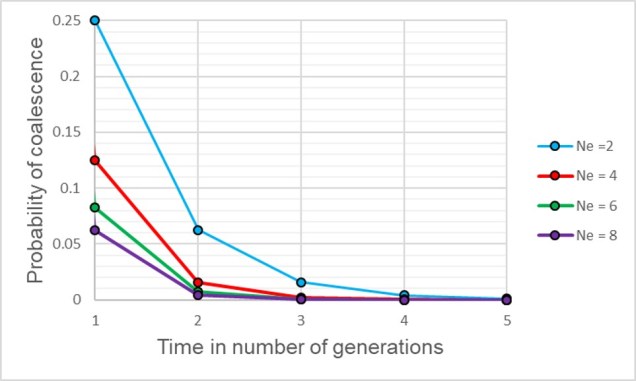
The probability of two alleles sharing a coalescent event back in time under different population sizes. Similar to above, there is a higher probability of an earlier coalescent event in smaller populations as the reduced number of ancestors means that alleles are more likely to ‘share’ an ancestor. However, over time this pattern consistently decreases under all population size scenarios.
Although this might seem mathematically complicated, the coalescent model provides us with a scenario of how we would expect different mutations to coalesce back in time if those idealistic scenarios are true. However, biology is rarely convenient and it’s unlikely that our study populations follow these patterns perfectly. By studying how our empirical data varies from the expectations, however, allows us to infer some interesting things about the history of populations and species.
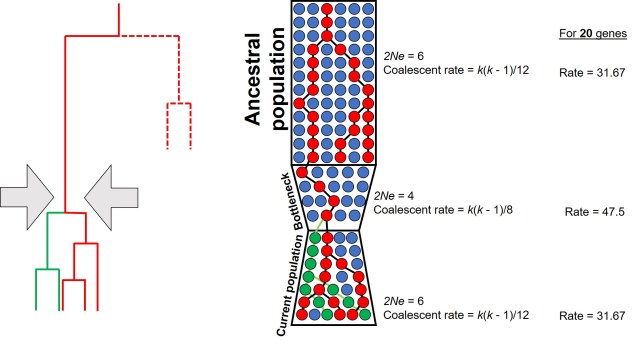
A diagram of how the coalescent can be used to detect bottlenecks in a single population (centre). In this example, we have contemporary population in which we are tracing the coalescence of two main alleles (red and green, respectively). Each circle represents a single individual (we are assuming only one allele per individual for simplicity, but for most animals there are up to two). Looking forward in time, you’ll notice that some red alleles go extinct just before the bottleneck: they are lost during the reduction in Ne. Because of this, if we measure the rate of coalescence (right), it is much higher during the bottleneck than before or after it. Another way this could be visualised is to generate gene trees for the alleles (left): populations that underwent a bottleneck will typically have many shorter branches and a long root, as many branches will be ‘lost’ by extinction (the dashed lines, which are not normally seen in a tree).
This makes sense from theoretical perspective as well, since strong genetic bottlenecks means that most alleles are lost. Thus, the alleles that we do have are much more likely to coalesce shortly after the bottleneck, with very few alleles that coalesce before the bottleneck event. These alleles are ones that have managed to survive the purge of the bottleneck, and are often few compared to the overarching patterns across the genome.
Testing migration (gene flow) across lineages
Another demographic factor we may wish to test is whether gene flow has occurred across our populations historically. Although there are plenty of allele frequency methods that can estimate contemporary gene flow (i.e. within a few generations), coalescent analyses can detect patterns of gene flow reaching further back in time.
A similar model of coalescence as above, but testing for migration rate (gene flow) in two recently diverged populations (right). In this example, when we trace two alleles (red and green) back in time, we notice that some individuals in Population 1 coalesce more recently with individuals of Population 2 than other individuals of Population 1 (e.g. for the red allele), and vice versa for the green allele. This can also be represented with gene trees (left), with dashed lines representing individuals from Population 2 and whole lines representing individuals from Population 1. This incomplete split between the two populations is the result of migration transferring genes from one population to the other after their initial divergence (also called ‘introgression’ or ‘horizontal gene transfer’).
Testing divergence time
In a similar vein, the coalescent can also be used to test how long ago the two contemporary populations diverged. Similar to gene flow, this is often included as an additional parameter on top of the coalescent model in terms of the number of generations ago. To convert this to a meaningful time estimate (e.g. in terms of thousands or millions of years ago), we need to include a mutation rate (the number of mutations per base pair of sequence per generation) and a generation time for the study species (how many years apart different generations are: for humans, we would typically say ~20-30 years).
An example of using the coalescent to test the divergence time between two populations, this time using three different alleles (red, green and yellow). Tracing back the coalescence of each alleles reveals different times (in terms of which generation the coalescence occurs in) depending on the allele (right). As above, we can look at this through gene trees (left), showing variation how far back the two populations (again indicated with bold and dashed lines respectively) split. The blue box indicates the range of times (i.e. a confidence interval) around which divergence occurred: with many more alleles, this can be more refined by using an ‘average’ and later related to time in years with a generation time.
While each of these individual concepts may seem (depending on how well you handle maths!) relatively simple, one critical issue is the interactive nature of the different factors. Gene flow, divergence time and population size changes will all simultaneously impact the distribution and frequency of alleles and thus the coalescent method. Because of this, we often use complex programs to employ the coalescent which tests and balances the relative contributions of each of these factors to some extent. Although the coalescent is a complex beast, improvements in the methodology and the programs that use it will continue to improve our ability to infer evolutionary history with coalescent theory.