Temperate Australia
Australia is renowned for its unique diversity of species, and likewise for the diversity of ecosystems across the island continent. Although many would typically associate Australia with the golden sandy beaches, palm trees and warm weather of the tropical east coast, other ecosystems also hold both beautiful and interesting characteristics. Even the regions that might typically seem the dullest – the temperate zones in the southern portion of the continent – themselves hold unique stories of the bizarre and wonderful environmental history of Australia.
The two temperate zones
Within Australia, the temperate zone is actually separated into two very distinct and separate regions. In the far south-western corner of the continent is the southwest Western Australia temperate zone, which spans a significant portion. In the southern eastern corner, the unnamed temperate zone spans from the region surrounding Adelaide at its westernmost point, expanding to the east and encompassing Tasmanian and Victoria before shifting northward into NSW. This temperate zones gradually develops into the sub-tropical and tropical climates of more northern latitudes in Queensland and across to Darwin.
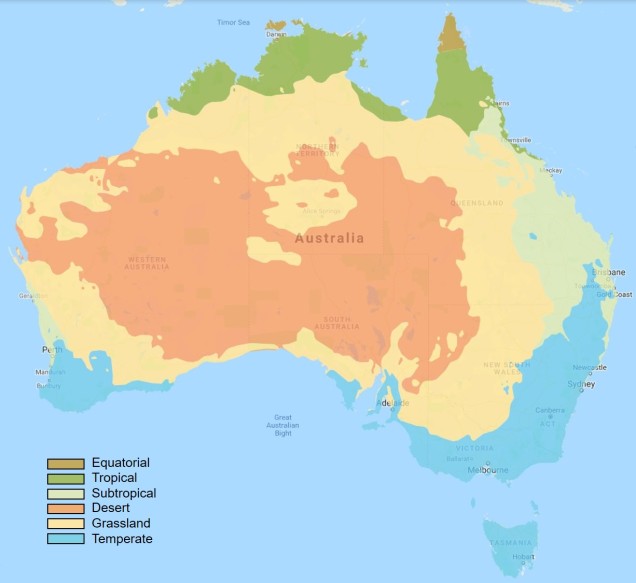
The divide separating these two regions might be familiar to some readers – the Nullarbor Plain. Not just a particularly good location for fossils and mineral ores, the Nullarbor Plain is an almost perfectly flat arid expanse that stretches from the western edge of South Australia to the temperate zone of the southwest. As the name suggests, the plain is totally devoid of any significant forestry, owing to the lack of available water on the surface. This plain is a relatively ancient geological structure, and finished forming somewhere between 14 and 16 million years ago when tectonic uplift pushed a large limestone block upwards to the surface of the crust, forming an effective drain for standing water with the aridification of the continent. Thus, despite being relatively similar bioclimatically, the two temperate zones of Australia have been disconnected for ages and boast very different histories and biota.
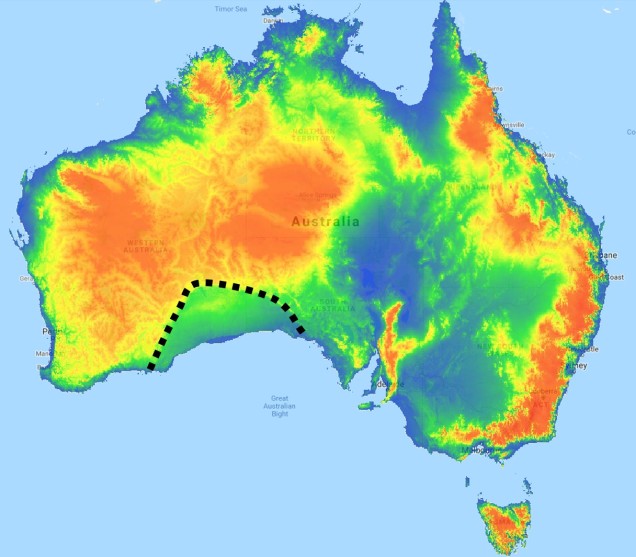
The hotspot of the southwest
The southwest temperate zone – commonly referred to as southwest Western Australia (SWWA) – is an island-like bioregion. Isolated from the rest of the temperate Australia, it is remarkably geologically simple, with little topographic variation (only the Darling Scarp that separates the lower coast from the higher elevation of the Darling Plateau), generally minor river systems and low levels of soil nutrients. One key factor determining complexity in the SWWA environment is the isolation of high rainfall habitats within the broader temperate region – think of islands with an island.
Despite the lack of geological complexity and the perceived diversity of the tropics, the temperate zone of SWWA is the only internationally recognised biodiversity hotspot within Australia. As an example, SWWA is inhabited by ~7,000 different plant species, half of which are endemic to the region. Not to discredit the impressive diversity of the rest of the continent, of course. So why does this area have even higher levels of species diversity and endemism than the rest of mainland Australia?
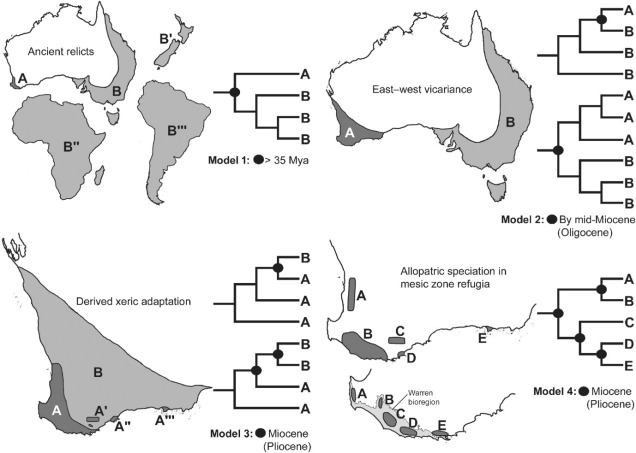
Well, a number of factors may play significant roles in determining this. One of these is the ancient and isolated nature of the region: SWWA has been separated from the rest of Australia for at least 14 million years, with many species likely originating much earlier than this. Because of this isolation, species occurring within SWWA have been allowed to undergo adaptive divergence from their east coast relatives, forming unique evolutionary lineages. Furthermore, the southwest corner of the continent was one of the last to break away from Antarctica in the dismantling of Gondwana >30 million years ago. Within the region more generally, isolation of mesic (wetter) habitats from the broader, arid (xeric) habitats also likely drove the formation of new species as distributions became fragmented or as species adapted to the new, encroaching xeric habitat. Together, this varies mechanisms all likely contributed in some way to the overall diversity of the region.
The temperate south-east of Australia
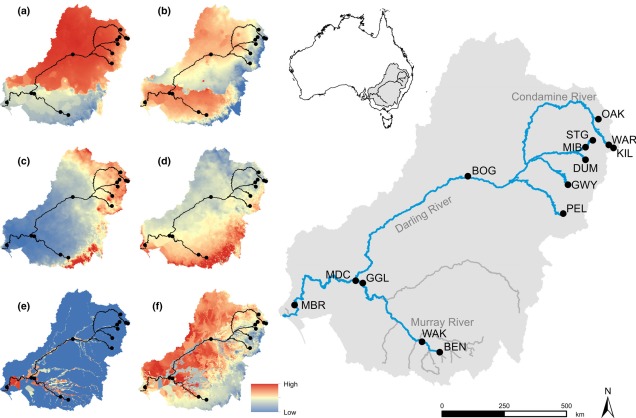
Contrastingly, the temperate region in the south-east of the continent is much more complex. For one, the topography of the zone is much more variable: there are a number of prominent mountain chains (such as the extended Great Dividing Range), lowland basins (such as the expansive Murray-Darling Basin) and variable valley and river systems. Similarly, the climate varies significantly within this temperate region, with the more northern parts featuring more subtropical climatic conditions with wetter and hotter summers than the southern end. There is also a general trend of increasing rainfall and lower temperatures along the highlands of the southeast portion of the region, and dry, semi-arid conditions in the western lowland region.
A complicated history
The south-east temperate zone is not only variable now, but has undergone some drastic environmental changes over history. Massive shifts in geology, climate and sea-levels have particularly altered the nature of the area. Even volcanic events have been present at some time in the past.
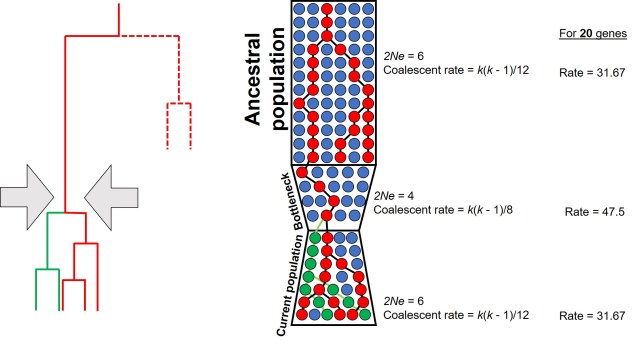
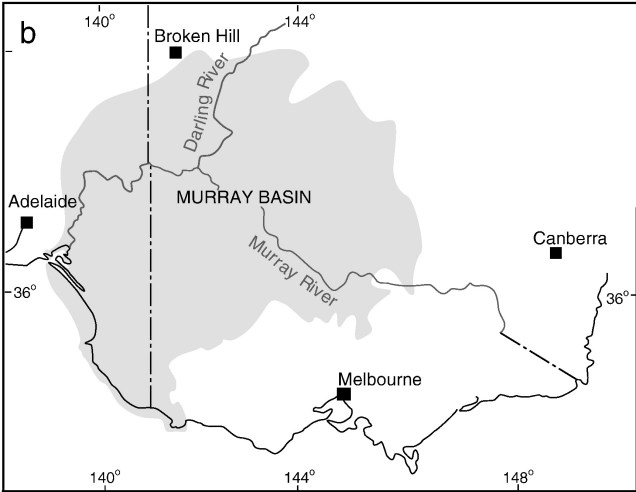
One key hydrological shift that massively altered the region was the paleo-megalake Bungunnia. Not just a list of adjectives, Bungunnia was exactly as it’s described: a historically massive lake that spread across a huge area prior to its demise ~1-2 million years ago. At its largest size, Lake Bungunnia reached an area of over 50,000 km2, spreading from its westernmost point near the current Murray mouth although to halfway across Victoria. Initially forming due to a tectonic uplift event along the coastal edge of the Murray-Darling Basin ~3.2 million years ago, damming the ancestral Murray River (which historically outlet into the ocean much further east than today). Over the next few million years, the size of the lake fluctuated significantly with climatic conditions, with wetter periods causing the lake to overfill and burst its bank. With every burst, the lake shrank in size, until a final break ~700,000 years ago when the ‘dam’ broke and the full lake drained.
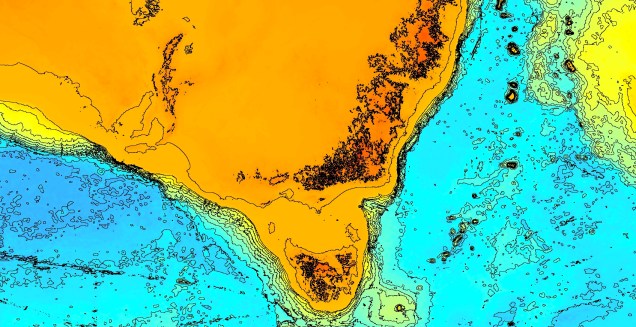
Another change in the historic environment readers may be more familiar with is the land-bridge that used to connect Tasmania to the mainland. Dubbed the Bassian Isthmus, this land-bridge appeared at various points in history of reduced sea-levels (i.e. during glacial periods in Pleistocene cycle), predominantly connecting via the still-above-water Flinders and Cape Barren Islands. However, at lower sea-levels, the land bridge spread as far west as King Island: central to this block of land was a large lake dubbed the Bass Lake (creative). The Bassian Isthmus played a critical role in the migration of many of the native fauna of Tasmania (likely including the Indigenous peoples of the now-island), and its submergence and isolation leads to some distinctive differences between Tasmanian and mainland biota. Today, the historic presence of the Bassian Isthmus has left a distinctive mark on the genetic make-up of many species native to the southeast of Australia, including dolphins, frogs, freshwater fishes and invertebrates.
Don’t underestimate the temperates
Although tropical regions get most of the hype for being hotspots of biodiversity, the temperate zones of Australia similarly boast high diversity, unique species and document a complex environmental history. Studying how the biota and environment of the temperate regions has changed over millennia is critical to predicting the future effects of climatic change across large ecosystems.