We’ve spent some time before discussing the nature of the term ‘species’ and what it means in reality. Of course, answers to questions in biology are always more complicated than we wish they might be, and despite the common nomenclature of the word ‘species’ the underlying definition is convoluted and variable.
The idea of using the genetic sequences of living organisms to understand the evolutionary history of species is a concept much repeated on The G-CAT. And it’s a fundamental one in phylogenetics, taxonomy and evolutionary biology. Often, we try to analyse the genetic differences between individuals, populations and species in a tree-like manner, with close tips being similar and more distantly separated branches being more divergent. However, this runs on one very key assumption; that the patterns we observe in our study genes matches the overall patterns of species evolution. But this isn’t always true, and before we can delve into that we have to understand the difference between a ‘gene tree’ and a ‘species tree’.
A gene tree or a species tree?
Our typical view of a phylogenetic tree is actually one of a ‘gene tree’, where we analyse how a particular gene (or set of genes) have changed over time between different individuals (within and across populations or species) based on our understanding of mutation and common ancestry.
However, a phylogenetic tree based on a single gene only demonstrates the history of that gene. What we assume in most cases is that the history of that gene matches the history of the species: that branches in the genetic tree mirror when different splits in species occurred throughout history.
The easiest way to conceptualise gene trees and species trees is to think of individual gene trees that are nested within an overarching species tree. In this sense, individual gene trees can vary from one another (substantially, even) but by looking at the overall trends of many genes we can see how the genome of the species have changed over time.
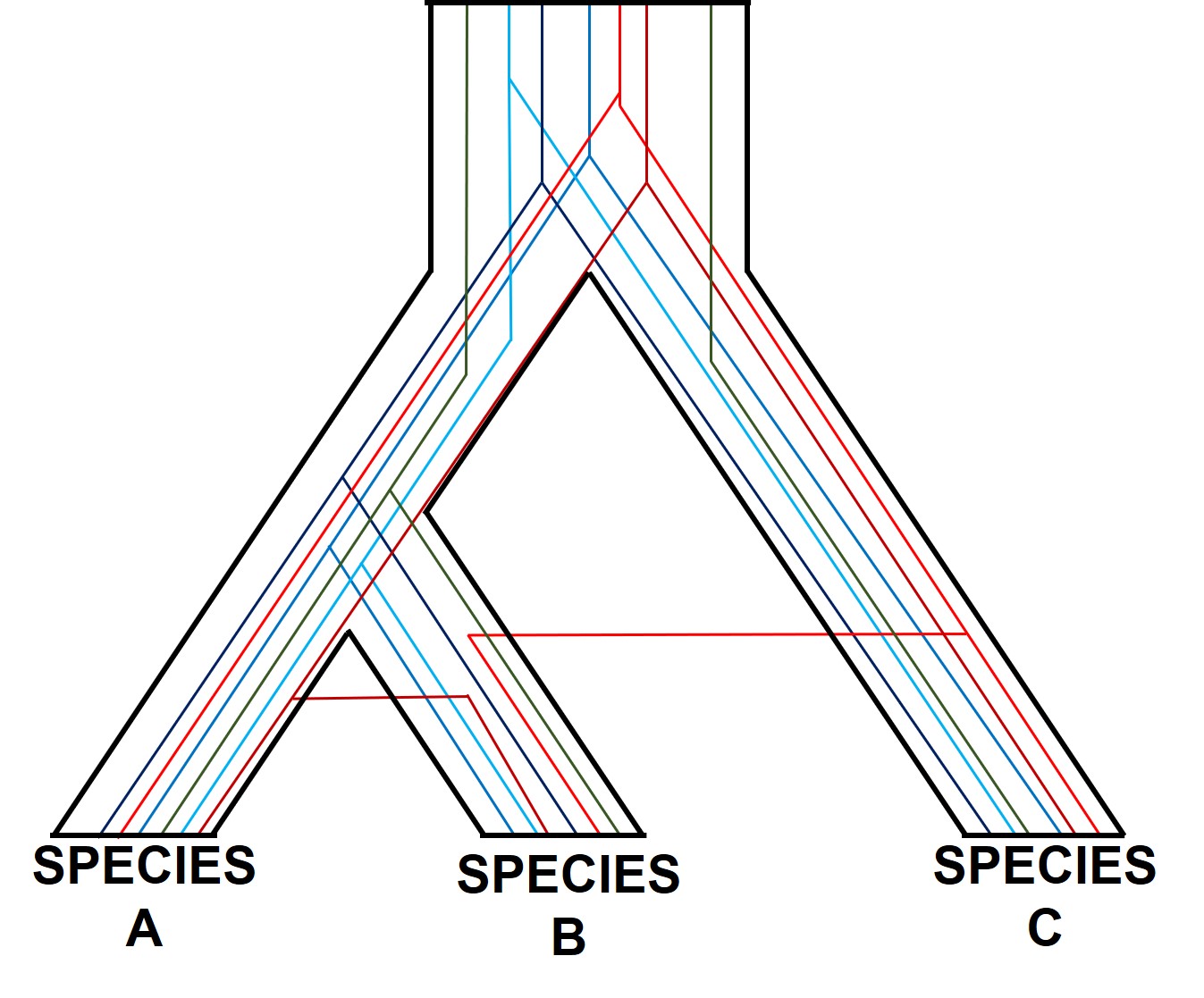
A (potentially familiar) depiction of individual gene trees (coloured lines) within the broader species tree (defined b the black boundaries). As you might be able to tell, the branching patterns of the different genes are not the same, and don’t always match the overarching species tree.
One of the most prolific, but more complicated, ways gene trees can vary from their overarching species tree is due to what we call ‘incomplete lineage sorting’. This is based on the idea that species and the genes that define them are constantly evolving over time, and that because of this different genes are at different stages of divergence between population and species. If we imagine a set of three related populations which have all descended from a single ancestral population, we can start to see how incomplete lineage sorting could occur. Our ancestral population likely has some genetic diversity, containing multiple alleles of the same locus. In a true phylogenetic tree, we would expect these different alleles to ‘sort’ into the different descendent populations, such that one population might have one of the alleles, a second the other, and so on, without them sharing the different alleles between them.
If this separation into new populations has been recent, or if gene flow has occurred between the populations since this event, then we might find that each descendent population has a mixture of the different alleles, and that not enough time has passed to clearly separate the populations. For this to occur, sufficient time for new mutations to occur and genetic drift to push different populations to differently frequent alleles needs to happen: if this is too recent, then it can be hard to accurately distinguish between populations. This can be difficult to interpret (see below figure for a visualisation of this), but there’s a great description of incomplete lineage sorting here.
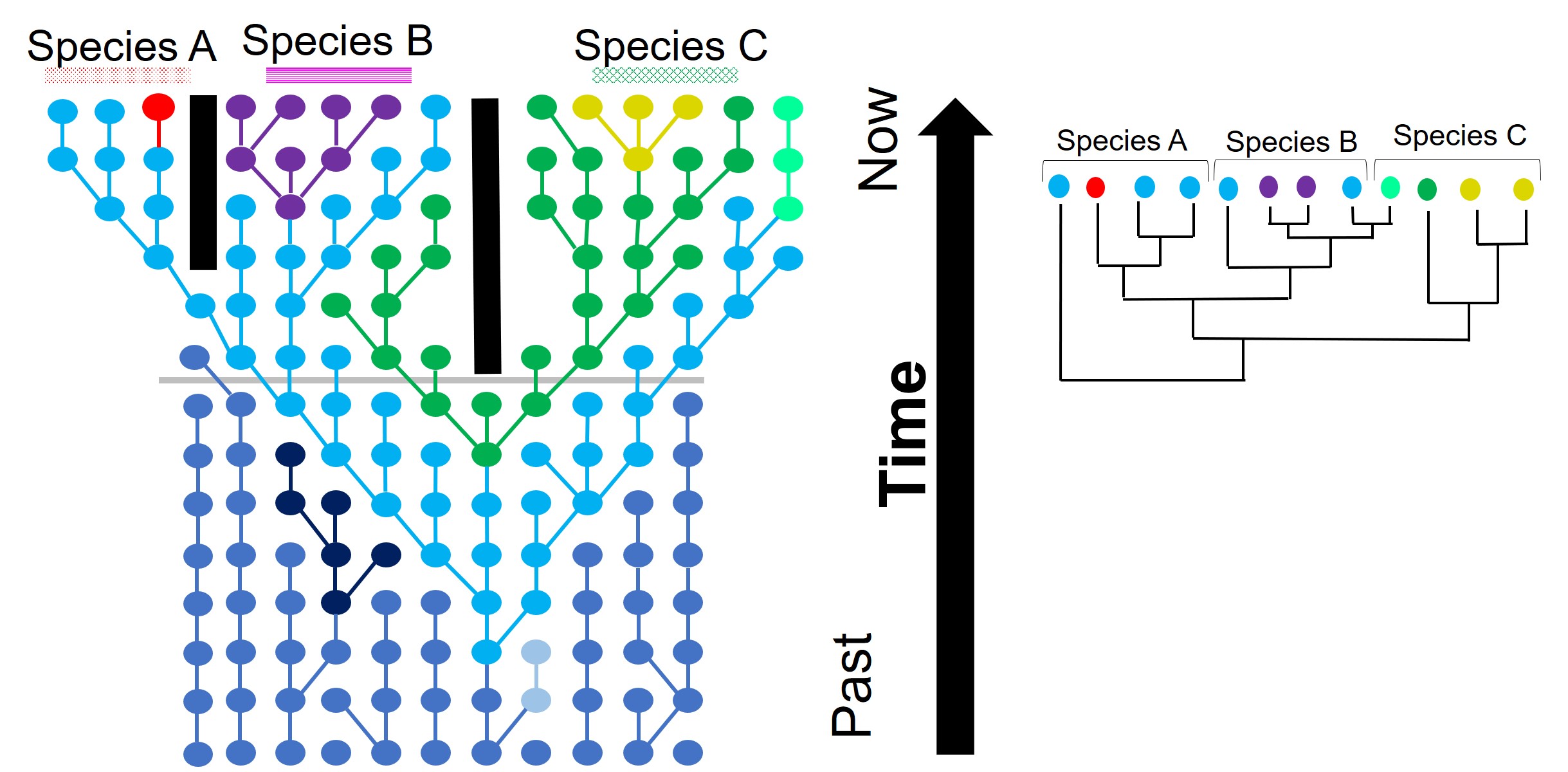
A demonstration of incomplete lineage sorting, generously adapted from a talk by fellow MELFU postdocs Dr Yuma (Jonathon) Sandoval-Castillo and Dr Catherine Attard. On the left is a depiction of a single gene coalescent tree over time: circles represent a single individual at a particular point in time (row) with the colours representing different alleles of that same gene. The tree shows how new mutations occur (colour changes along the branches) and spread throughout the descendent populations. In this example, we have three recently separated species, with a good number of different alleles. However, when we study these alleles in tree form (the phylogeny on the right), we see that the branches themselves don’t correlate well with the boundaries of the species. For example, the teal allele found within Species C is actually more similar to Species B alleles (purple and blue) than any other Species B alleles, based on the order and patterns of these mutations.
Hybridisation and horizontal transfer
Another way individual genes may become incongruent with other genes is through another phenomenon we’ve discussed before: hybridisation (or more specifically, introgression). When two individuals from different species breed together to form a ‘hybrid’, they join together what was once two separate gene pools. Thus, the hybrid offspring has (if it’s a first generation hybrid, anyway) 50% of genes from Species A and 50% of genes from Species B. In terms of our phylogenetic analysis, if we picked one gene randomly from the hybrid, we have 50% of picking a gene that reflects the evolutionary history of Species A, and 50% chance of picking a gene that reflects the evolutionary history of Species B. This would change how our outputs look significantly: if we pick a Species A gene, our ‘hybrid’ will look (genetically) very, very similar to Species A. If we pick a Species B gene, our ‘hybrid’ will look like a Species B individual instead. Naturally, this can really stuff up our interpretations of species boundaries, distributions and identities.
An example of hybridisation leading to gene tree incongruence with our favourite colourful fish. A) We have a hybridisation event between a red fish (Species A) and a green fish (Species B), resulting in a hybrid species (‘Species’ H). The red fish genome is indicated by the yellow DNA, the green fish genomes by the blue DNA, and the hybrid orange fish has a mixture of these two. B) If we sampled one set of genes in the hybrid, we might select a gene that originated from the red fish, showing that the hybrid is identical (or very similar) the Species A. D) Conversely, if we sampled a gene originating from the green fish, the resultant phylogeny might show that the hybrid is the same as Species B. C) If we consider these two patterns in combination, which see the true pattern of species formation, which is not a clear dichotomous tree and rather a mixture of the two sets of trees.
This can have a profound impact as paralogous genes are difficult to detect: if there has been a gene duplication early in the evolutionary history of our phylogenetic tree, then many (or all) of our study samples will have two copies of said gene. Since they look similar in sequence, there’s all possibility that we pick Variant 1 in some species and Variant 2 in other species. Being unable to tell them apart, we can have some very weird and abstract results within our tree. Most importantly, different samples with the same duplicated variant will seem similar to one another (e.g. have evolved from a common ancestor more recently) than it will to any sample of the other variant (even if they came from the exact same species)!
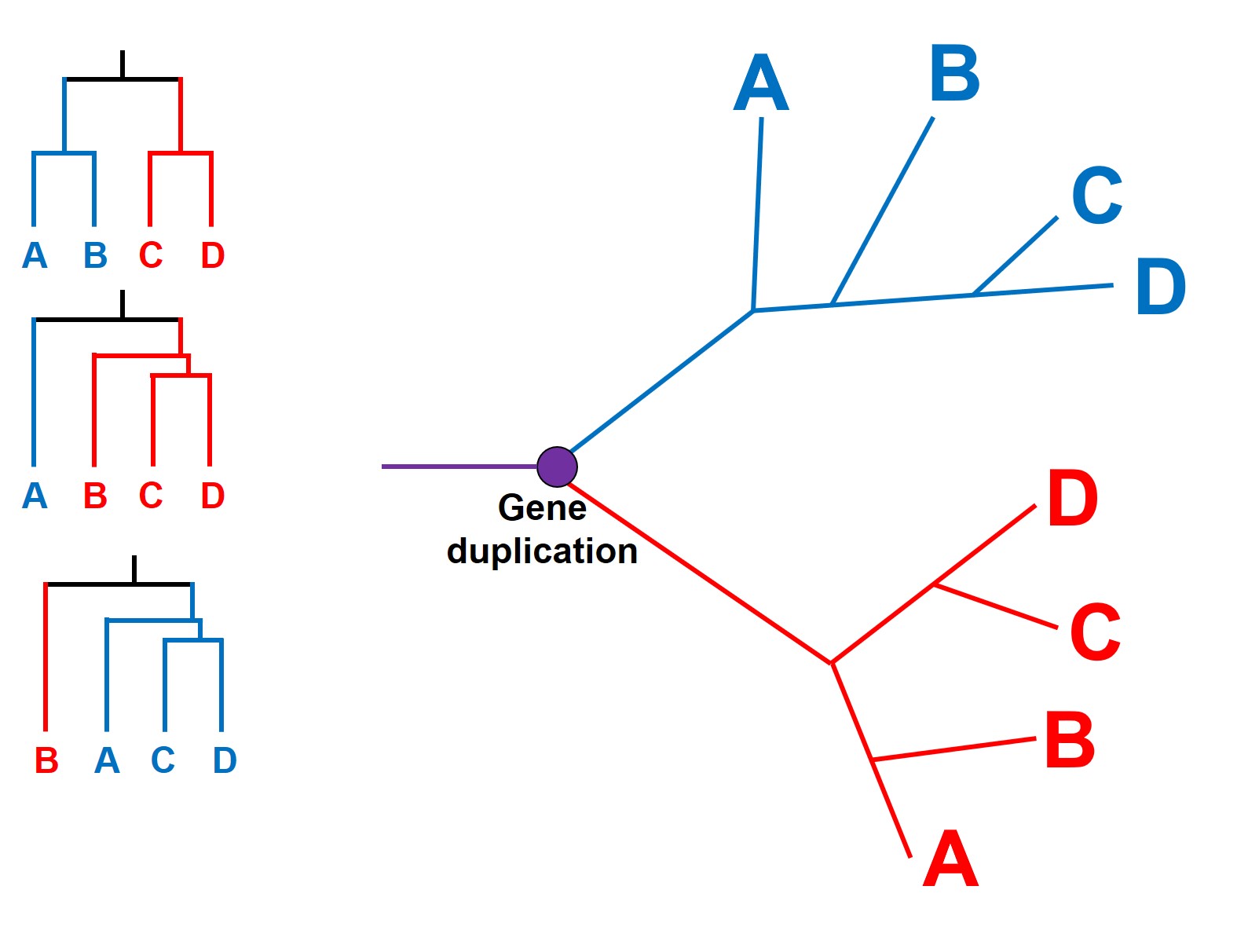
An example of how paralogous genes can confound species tree. We start with a single (purple) gene: at a particular point in time, this gene duplicates into a red and a blue form. Each of these genes then evolve and spread into four separate descendent species (A, B, C and D) but not in entirely the same way. However, since both the red and blue genetic sequences are similar, if we took a single gene from each species we might (somewhat randomly) sequence either the red or the blue copy. The different phylogenetic trees on the right demonstrate how different combinations of red and blue genes give very different patterns, since all blue copies will be more related to other blue genes than to the red gene of the same species. E.g. a blueA and a blueC are more similar than a blueA and a redA.
Overcoming incongruence with genomics
Although a tricky conundrum in phylogenetics and evolutionary genetics broadly, gene tree incongruence can largely be overcome with using more loci. As the random changes of any one locus has a smaller effect of the larger total set of loci, the general and broad patterns of evolutionary history can become clearer. Indeed, understanding how many loci are affected by what kind of process can itself become informative: large numbers of introgressed loci can indicate whether hybridisation was recent, strong, or biased towards one species over another, for example. As with many things, the genomic era appears poised to address the many analytical issues and complexities of working with genetic data.
This is the fourth (and final) part of the miniseries on the genetics and process of speciation. To start from Part One, click here.
In last week’s post, we looked at how we can use genetic tools to understand and study the process of speciation, and particularly the transition from populations to species along the speciation continuum. Following on from that, the question of “how many species do I have?” can be further examined using genetic data. Sometimes, it’s entirely necessary to look at this question using genetics (and genomics).
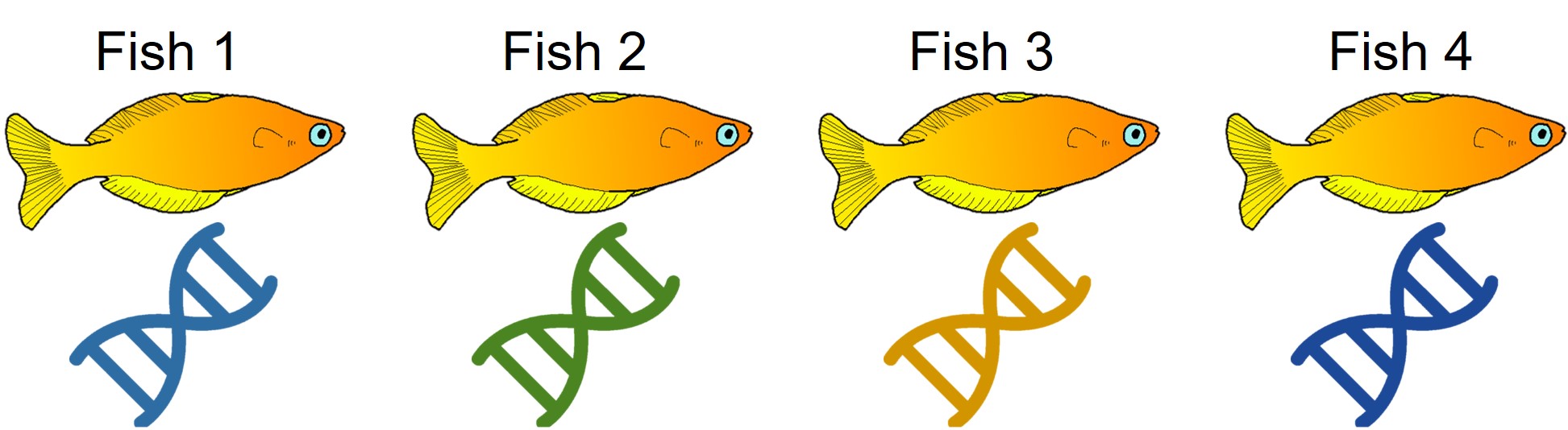
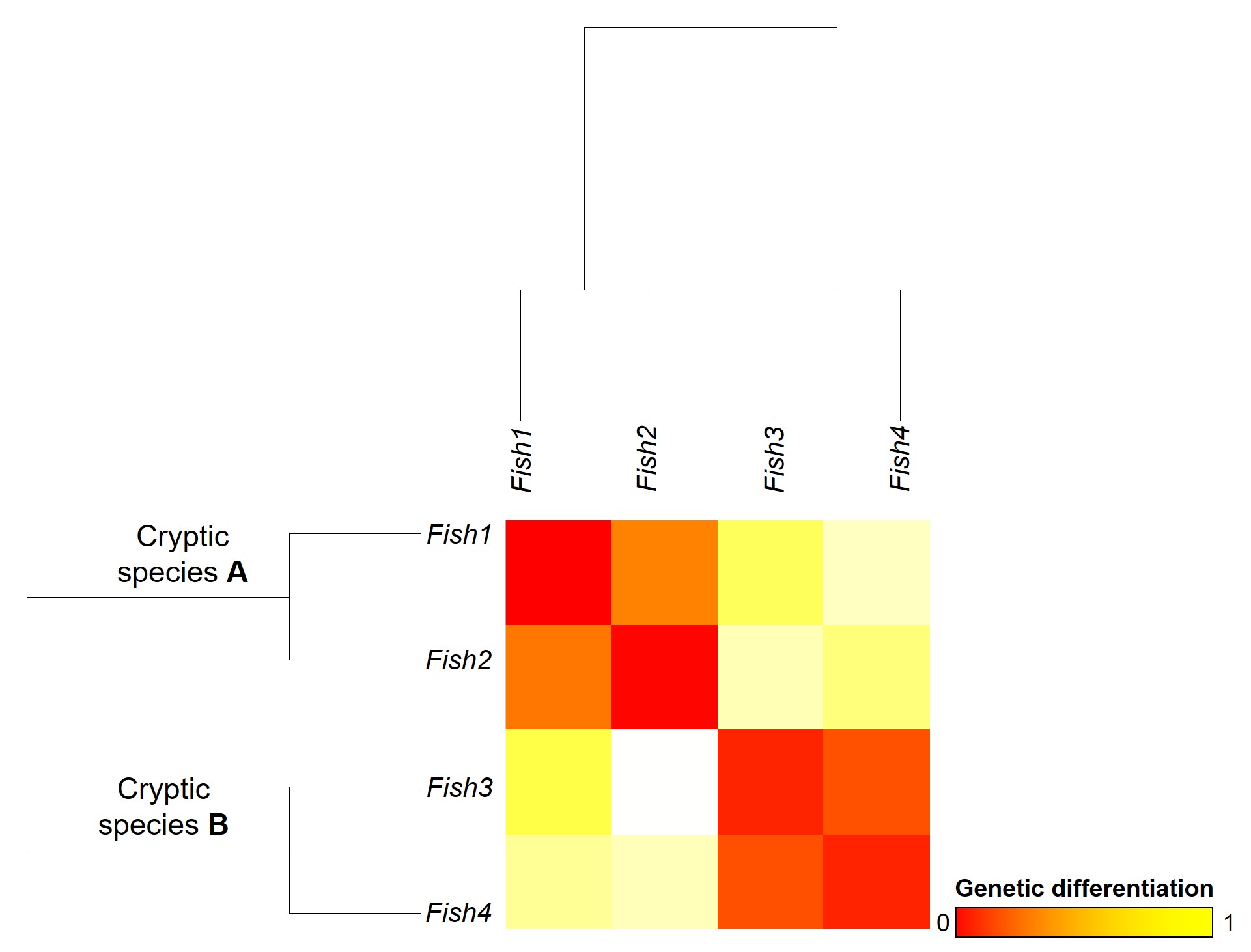
An example of cryptic species. All four fish in this figure are morphologically identical to one another, but they differ in their underlying genetic variation (indicated by the different colours of DNA). Thus, from looking at these fish alone we would not perceive any differences, but their genetic make-up might suggest that there are more than one species…
The level of genetic differentiation between the fish in the above example. The phylogenies on the left and top of the figure demonstrate the evolutionary relationships of these four fish. The matrix shows a heatmap of the level of differences between different pairwise comparisons of all four fish: red squares indicate zero genetic differences (such as when comparing a fish to itself; the middle diagonal) whilst yellow squares indicate increasingly higher levels of genetic differentiation (with bright yellow = all differences). By comparing the different fish together, we can see that Fish 1 and 2, and Fish 3 and 4, are relatively genetically similar to one another (red-deep orange). However, other comparisons show high level of genetic differences (e.g. 1 vs 3 and 1 vs 4). Based on this information, we might suggest that Fish 1 and 2 belong to one cryptic species (A) and Fish 3 and 4 belong to a second cryptic species (B).
Genetic tools to study species: the ‘Barcode of Life’
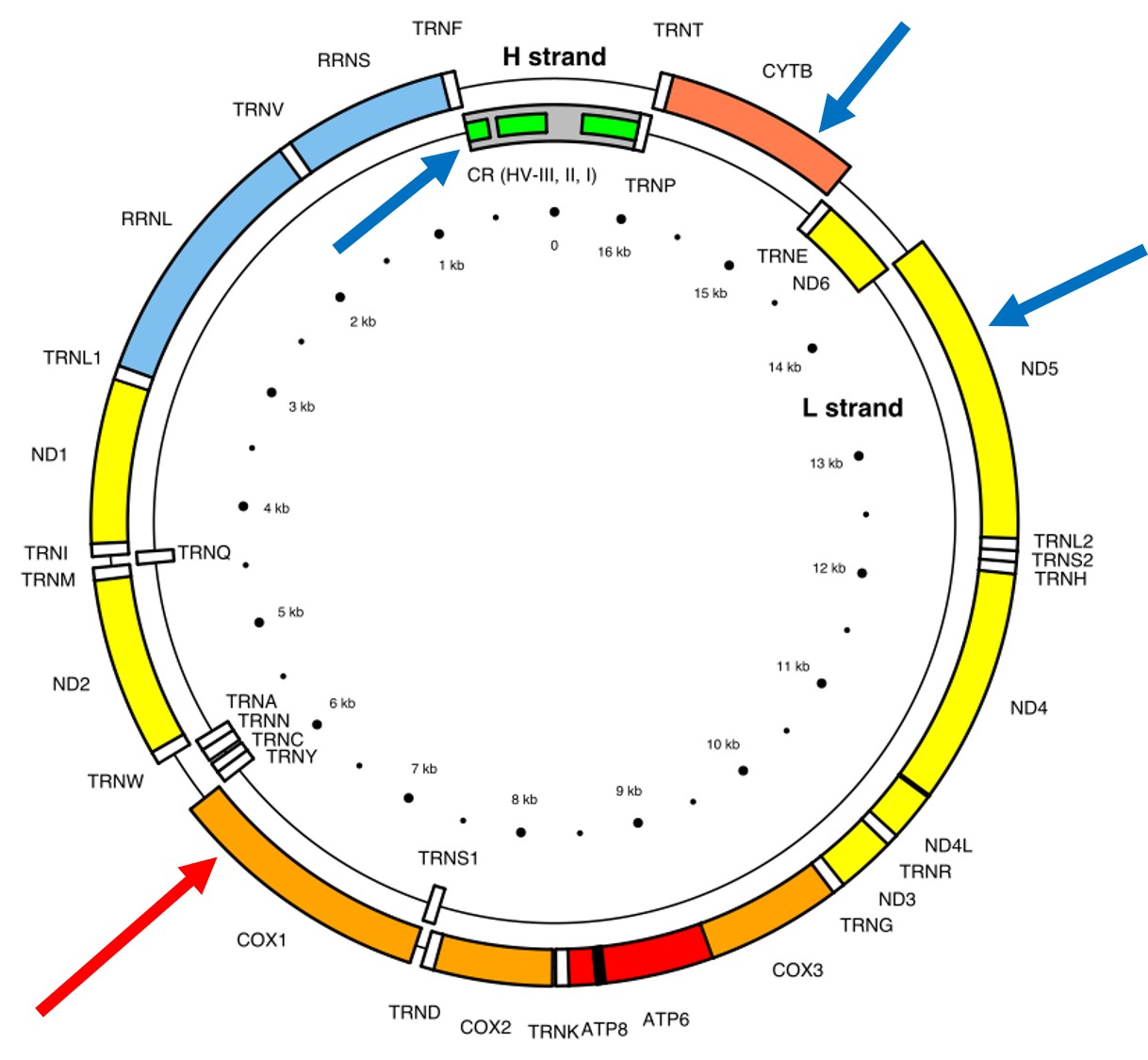
A classically employed method that uses DNA to detect and determine species is referred to as the ‘Barcode of Life’. This uses a very specific fragment of DNA from the mitochondria of the cell: the cytochrome c oxidase I gene, CO1. This gene is made of 648 base pairs and is found pretty well universally: this and the fact that CO1 evolves very slowly make it an ideal candidate for easily testing the identity of new species. Additionally, mitochondrial DNA tends to be a bit more resilient than its nuclear counterpart; thus, small or degraded tissue samples can still be sequenced for CO1, making it amenable to wildlife forensics cases. Generally, two sequences will be considered as belonging to different species if they are certain percentage different from one another.
The full (annotated) mitochondrial genome of humans, with the different genes within it labelled. The CO1 gene is labelled with the red arrow (sometimes also referred to as COX1) whilst blue arrows point to other genes often used in phylogenetic or taxonomic studies, depending on the group or species in question.
Despite the apparent benefits of CO1, there are of course a few drawbacks. Most of these revolve around the mitochondrial genome itself. Because mitochondria are passed on from mother to offspring (and not at all from the father), it reflects the genetic history of only one sex of the species. Secondly, the actual cut-off for species using CO1 barcoding is highly contentious and possibly not as universal as previously suggested. Levels of sequence divergence of CO1 between species that have been previously determined to be separate (through other means) have varied from anywhere between 2% to 12%. The actual translation of CO1 sequence divergence and species identity is not all that clear.
Gene tree – species tree incongruences
One particularly confounding aspect of defining species based on a single gene, and with using phylogenetic-based methods, is that the history of that gene might not actually be reflective of the history of the species. This can be a little confusing to think about but essentially leads to what we call “gene tree – species tree incongruence”. Different evolutionary events cause different effects on the underlying genetic diversity of a species (or group of species): while these may be predictable from the genetic sequence, different parts of the genome might not be as equally affected by the same exact process.
A classic example of this is hybridisation. If we have two initial species, which then hybridise with one another, we expect our resultant hybrids to be approximately made of 50% Species A DNA and 50% Species B DNA (if this is the first generation of hybrids formed; it gets a little more complicated further down the track). This means that, within the DNA sequence of the hybrid, 50% of it will reflect the history of Species A and the other 50% will reflect the history of Species B, which could differ dramatically. If we randomly sample a single gene in the hybrid, we will have no idea if that gene belongs to the genealogy of Species A or Species B, and thus we might make incorrect inferences about the history of the hybrid species.
A diagram of gene tree – species tree incongruence. Each individual coloured line represents a single gene as we trace it back through time; these are mostly bound within the limits of species divergences (the black borders). For many genes (such as the blue ones), the genes resemble the pattern of species divergences very well, albeit with some minor differences in how long ago the splits happened (at the top of the branches). However, the red genes contrast with this pattern, with clear movement across species (from A and C into B): this represents genes that have been transferred by hybridisation. The green line represents a gene affected by what we call incomplete lineage sorting; that is, we cannot trace it back far enough to determine exactly how/when it initially diverged and so there are still two separate green lines at the very top of the figure. You can think of each line as a separate phylogenetic tree, with the overarching species tree as the average pattern of all of the genes.
There are a number of other processes that could similarly alter our interpretations of evolutionary history based on analysing the genetic make-up of the species. The best way to handle this is simply to sample more genes: this way, the effect of variation of evolutionary history in individual genes is likely to be overpowered by the average over the entire gene pool. We interpret this as a set of individual gene trees contained within a species tree: although one gene might vary from another, the overall picture is clearer when considering all genes together.
Species delimitation
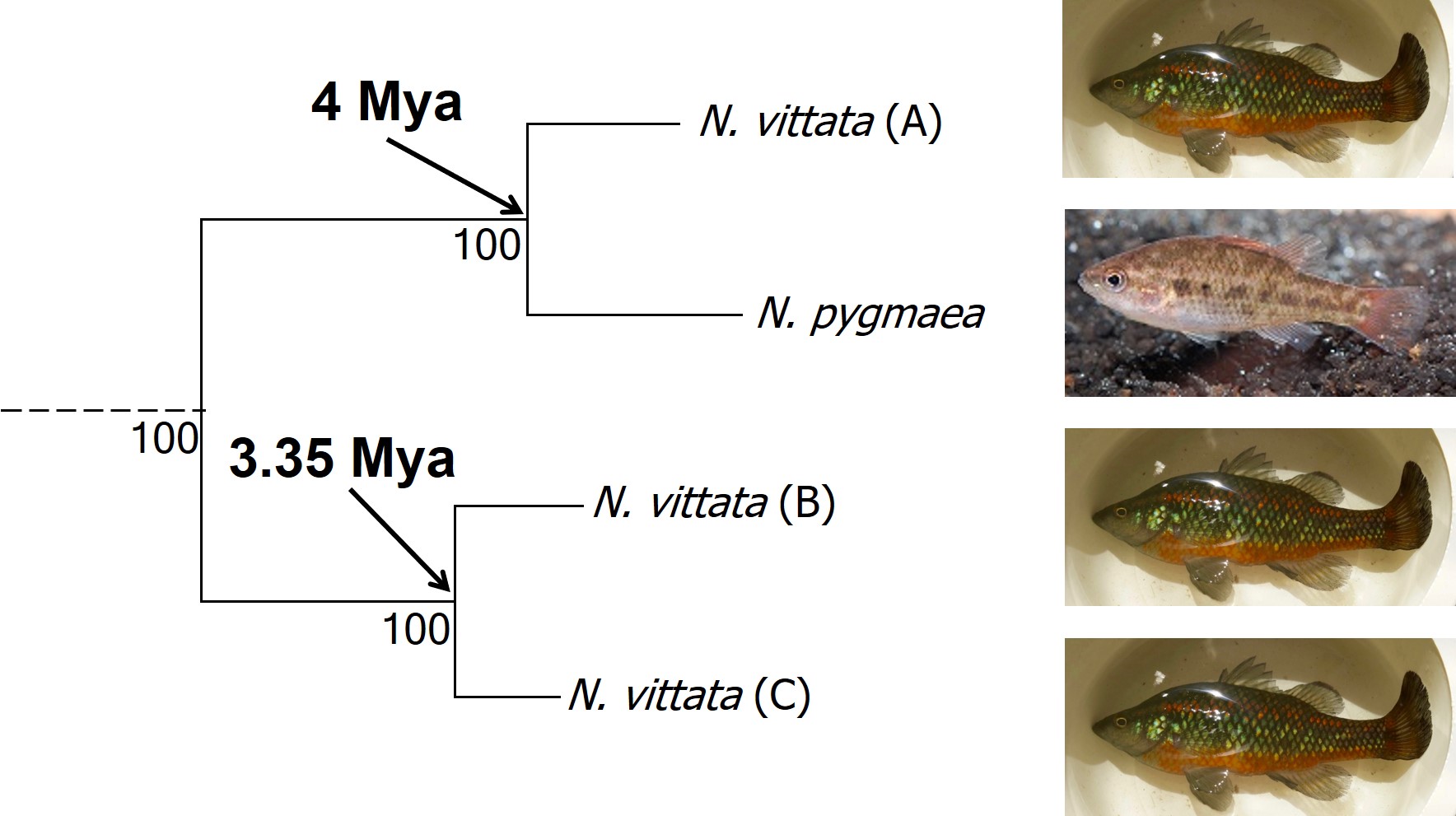
In earlier posts on The G-CAT, I’ve discussed the biogeographical patterns unveiled by my Honours research. Another key component of that paper involved using statistical modelling to determine whether cryptic species were present within the pygmy perches. I didn’t exactly elaborate on that in that section (mostly for simplicity), but this type of analysis is referred to as ‘species delimitation’. To try and simplify complicated analyses, species delimitation methods evaluate possible numbers and combinations of species within a particular dataset and provides a statistical value for which configuration of species is most supported. One program that employs species delimitation is Bayesian Phylogenetics and Phylogeography(BPP): to do this, it uses a plethora of information from the genetics of the individuals within the dataset. These include how long ago the different populations/species separated; which populations/species are most related to one another; and a pre-set minimum number of species (BPP will try to combine these in estimations, but not split them due to computational restraints). This all sounds very complex (and to a degree it is), but this allows the program to give you a statistical value for what is a species and what isn’t based on the genetics and statistical modelling.
The cryptic species of pygmy perches identified within my research paper. This represents part of the main phylogenetic tree result, with the estimates of divergence times from other analyses included. The pictures indicate the physiology of the different ‘species’: Nannoperca pygmaea is morphologically different to the other species of Nannoperca vittata. Species delimitation analysis suggested all four of these were genetically independent species; at the very least, it is clear that there must be at least 2 species of Nannoperca vittata since A is more related to N. pygmaea than to other N. vittata species. Photo credits: N. vittata = Chris Lamin; N. pygmaea = David Morgan.
The end result of a BPP run is usually reported as a species tree (e.g. a phylogenetic tree describing species relationships) and statistical support for the delimitation of species (0-1 for each species). Because of the way the statistical component of BPP works, it has been found to give extremely high support for species identities. This has been criticised as BPP can, at time, provide high statistical support for genetically isolated lineages (i.e. divergent populations) which are not actually species.
Improving species identities with integrative taxonomy
Due to this particular drawback, and the often complex nature of species identity, using solely genetic information such as species delimitation to define species is extremely rare. Instead, we use a combination of different analytical techniques which can include genetic-based evaluations to more robustly assign and describe species. In my own paper example, we suggested that up to three ‘species’ of N. vittata that were determined as cryptic species by BPP could potentially exist pending on further analyses. We did not describe or name any of the species, as this would require a deeper delve into the exact nature and identity of these species.
As genetic data and analytical techniques improve into the future, it seems likely that our ability to detect and determine species boundaries will also improve. However, the additional supported provided by alternative aspects such as ecology, behaviour and morphology will undoubtedly be useful in the progress of taxonomy.