This is the fourth (and final) part of the miniseries on the genetics and process of speciation. To start from Part One, click here.
In last week’s post, we looked at how we can use genetic tools to understand and study the process of speciation, and particularly the transition from populations to species along the speciation continuum. Following on from that, the question of “how many species do I have?” can be further examined using genetic data. Sometimes, it’s entirely necessary to look at this question using genetics (and genomics).
Cryptic species
A concept that I’ve mentioned briefly previously is that of ‘cryptic species’. These are species which are identifiable by their large genetic differences, but appear the same based on morphological, behavioural or ecological characteristics. Cryptic species often arise when a single species has become fragmented into several different populations which have been isolated for a long time from another. Although they may diverge genetically, this doesn’t necessarily always translate to changes in their morphology, ecology or behaviour, particularly if these are strongly selected for under similar environmental conditions. Thus, we need to use genetic methods to be able to detect and understand these species, as well as later classify and describe them.

Genetic tools to study species: the ‘Barcode of Life’
A classically employed method that uses DNA to detect and determine species is referred to as the ‘Barcode of Life’. This uses a very specific fragment of DNA from the mitochondria of the cell: the cytochrome c oxidase I gene, CO1. This gene is made of 648 base pairs and is found pretty well universally: this and the fact that CO1 evolves very slowly make it an ideal candidate for easily testing the identity of new species. Additionally, mitochondrial DNA tends to be a bit more resilient than its nuclear counterpart; thus, small or degraded tissue samples can still be sequenced for CO1, making it amenable to wildlife forensics cases. Generally, two sequences will be considered as belonging to different species if they are certain percentage different from one another.
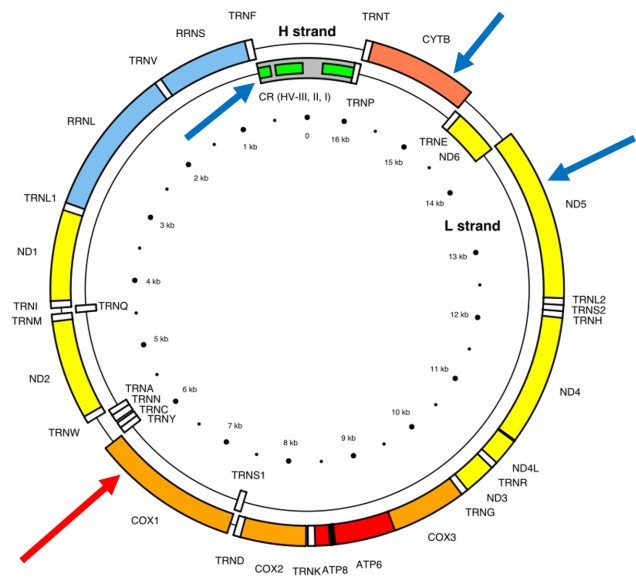
Despite the apparent benefits of CO1, there are of course a few drawbacks. Most of these revolve around the mitochondrial genome itself. Because mitochondria are passed on from mother to offspring (and not at all from the father), it reflects the genetic history of only one sex of the species. Secondly, the actual cut-off for species using CO1 barcoding is highly contentious and possibly not as universal as previously suggested. Levels of sequence divergence of CO1 between species that have been previously determined to be separate (through other means) have varied from anywhere between 2% to 12%. The actual translation of CO1 sequence divergence and species identity is not all that clear.
Gene tree – species tree incongruences
One particularly confounding aspect of defining species based on a single gene, and with using phylogenetic-based methods, is that the history of that gene might not actually be reflective of the history of the species. This can be a little confusing to think about but essentially leads to what we call “gene tree – species tree incongruence”. Different evolutionary events cause different effects on the underlying genetic diversity of a species (or group of species): while these may be predictable from the genetic sequence, different parts of the genome might not be as equally affected by the same exact process.
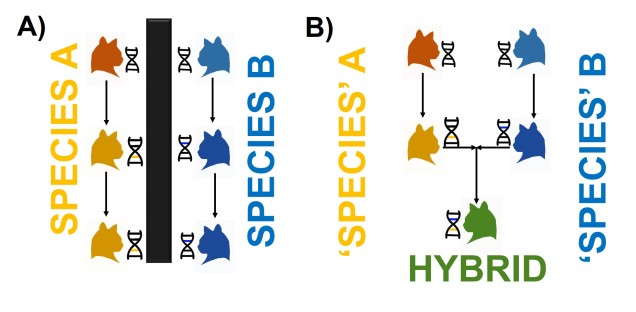
A classic example of this is hybridisation. If we have two initial species, which then hybridise with one another, we expect our resultant hybrids to be approximately made of 50% Species A DNA and 50% Species B DNA (if this is the first generation of hybrids formed; it gets a little more complicated further down the track). This means that, within the DNA sequence of the hybrid, 50% of it will reflect the history of Species A and the other 50% will reflect the history of Species B, which could differ dramatically. If we randomly sample a single gene in the hybrid, we will have no idea if that gene belongs to the genealogy of Species A or Species B, and thus we might make incorrect inferences about the history of the hybrid species.
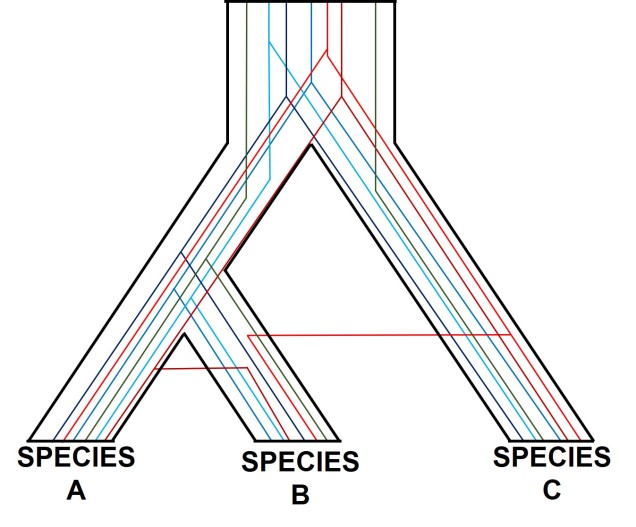
There are a number of other processes that could similarly alter our interpretations of evolutionary history based on analysing the genetic make-up of the species. The best way to handle this is simply to sample more genes: this way, the effect of variation of evolutionary history in individual genes is likely to be overpowered by the average over the entire gene pool. We interpret this as a set of individual gene trees contained within a species tree: although one gene might vary from another, the overall picture is clearer when considering all genes together.
Species delimitation
In earlier posts on The G-CAT, I’ve discussed the biogeographical patterns unveiled by my Honours research. Another key component of that paper involved using statistical modelling to determine whether cryptic species were present within the pygmy perches. I didn’t exactly elaborate on that in that section (mostly for simplicity), but this type of analysis is referred to as ‘species delimitation’. To try and simplify complicated analyses, species delimitation methods evaluate possible numbers and combinations of species within a particular dataset and provides a statistical value for which configuration of species is most supported. One program that employs species delimitation is Bayesian Phylogenetics and Phylogeography (BPP): to do this, it uses a plethora of information from the genetics of the individuals within the dataset. These include how long ago the different populations/species separated; which populations/species are most related to one another; and a pre-set minimum number of species (BPP will try to combine these in estimations, but not split them due to computational restraints). This all sounds very complex (and to a degree it is), but this allows the program to give you a statistical value for what is a species and what isn’t based on the genetics and statistical modelling.
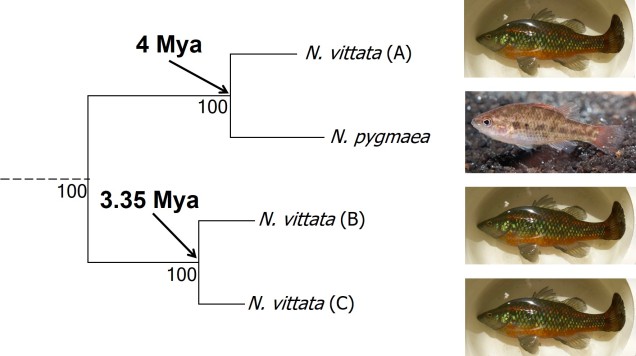
The end result of a BPP run is usually reported as a species tree (e.g. a phylogenetic tree describing species relationships) and statistical support for the delimitation of species (0-1 for each species). Because of the way the statistical component of BPP works, it has been found to give extremely high support for species identities. This has been criticised as BPP can, at time, provide high statistical support for genetically isolated lineages (i.e. divergent populations) which are not actually species.
Improving species identities with integrative taxonomy
Due to this particular drawback, and the often complex nature of species identity, using solely genetic information such as species delimitation to define species is extremely rare. Instead, we use a combination of different analytical techniques which can include genetic-based evaluations to more robustly assign and describe species. In my own paper example, we suggested that up to three ‘species’ of N. vittata that were determined as cryptic species by BPP could potentially exist pending on further analyses. We did not describe or name any of the species, as this would require a deeper delve into the exact nature and identity of these species.
As genetic data and analytical techniques improve into the future, it seems likely that our ability to detect and determine species boundaries will also improve. However, the additional supported provided by alternative aspects such as ecology, behaviour and morphology will undoubtedly be useful in the progress of taxonomy.